

Software Development
10
Mins
Top 10 Android App Development Companies in Pune 2026
Discover the most reliable Android app development companies in Pune that help businesses build scalable mobile solutions.

Most companies deal with a mix of files every day. PDFs, bank statements, emails, invoices, spreadsheets, images, and a lot more. All of these contain valuable information, but the data doesn’t help anyone until it’s extracted and appropriately organized. That’s the real challenge.
This blog explains why scalable document parsing is essential, what types of documents companies parse in real-world scenarios, the evolution of parsing from rule-based scripts to AI-powered document parsing systems, and why scala
Every day, your team wastes hours on tasks that shouldn't exist.
Finance teams manually type transaction details from bank statements into spreadsheets.
Operations staff copy invoice data line by line into ERP systems.
Compliance teams hunt through hundreds of PDFs searching for a single clause or date.
Your skilled team members spend their day manually copying information without analyzing it or taking the right action, which wastes 15-30% of their time.
Human errors such as reading the wrong number, an unchecked transaction, or a misprint in a client name can cause payment failures. That will affect compliance regulations and leave customers unsatisfied.
If a report takes more than 2 days to compile, it will delay decisions, causing you to fall behind competitors.
To solve a problem, you don't need an army, but a few skilled people are enough to figure out the root problem quickly.
Suppose you have significant information visualized as patterns, trends, and opportunities. However, they're documented as PDFs and images, which makes it difficult for analytics tools to edit or modify them.
The businesses winning today aren't processing documents faster manually. They've eliminated manual processing through AI powered parsing systems.
We know the system can’t parse and process data in human language. For proper technical functioning, it needs to be converted to a machine-readable format that the system can understand. Undoubtedly, we need scalable document processing tools like Parser. It captures the essential information like numbers, names, dates, or tables and interprets them into clean, structured data.
JSON for APIs and applications
Database tables for storage and querying
Structured records for analytics and automation
Normalized formats for consistency across systems

Companies handle more unstructured data than they realize. Many documents can’t be read directly by software, so someone has to do it manually.
This is slow and tiring, and errors are common.
A scalable document parser eliminates this step by automatically extracting the data. It gives you neat, ready-to-use information that can be imported directly into your system.
The data you receive wasn't designed for computers. It was designed for humans to read on paper or screens.
Even the "same" document varies between vendors, banks, and versions. One invoice template from HDFC won't match one from ICICI.
Your business deals with:
PDFs from vendors
Excel exports from accounting
Scanned documents from customers
HTML from websites
API responses from partners
Images with text that needs extraction
Each source demands its own parsing strategy.
Processing thousands of documents daily by hand? That's expensive, slow, and error-prone.
Automated parsing delivers:
Higher accuracy
Faster operations
Lower costs
As businesses grow, the variety and volume of documents they handle only increase.
From financial reports to customer onboarding files, every department depends on accurate data extraction.
This is why it’s essential to understand what types of documents companies actually need to parse in the real world.
Any time a business converts an unstructured document into usable data, there's a parser working behind the scenes.
Whether we talk about financial institutions that process thousands of statements daily or e-commerce platforms that track competitor pricing, parsers are the invisible drivers powering modern business automation.
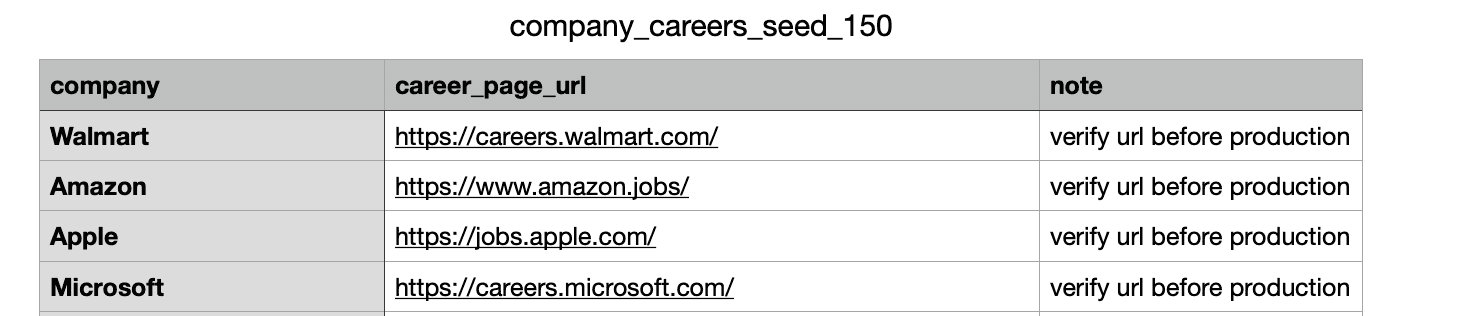
Across different industries and organizations for different operations following type of documents parsed:
Bank Statements, Credit Card Statements, Invoices & Bills, Loan Statements & EMI Schedules, Insurance Policy Documents, Tax Documents (Form 16, 16A, 26AS), Payslips & Salary Statements, CAS/CAMS/NSDL Statements, Contract Notes (Stock Trading), Demat Account Statements,Portfolio Reports & Wealth Statements, Fixed Deposit & Investment Receipts, Cheques & Payment Instruments, Letter of Credit & Bank Guarantees, etc.
Invoices & Bills, Purchase Orders, Expense Reports, KYC Documents, Legal Agreements & Contracts, Compliance Documents
Delivery Challans, Shipping Manifests, E-way Bills, Freight Bills & Transportation Invoices
Resumes/CVs, Offer Letters, Employee Onboarding Forms, Timesheets & Attendance Records
Product Catalogs, Order Confirmations, Return & Refund Requests, Inventory Reports
Prescriptions, Lab Reports, Insurance Claims, Medical Bills
Mark Sheets & Transcripts, Certificates & Diplomas, Fee Receipts
Sale Deeds & Purchase Agreements, Rental Agreements, Property Tax Receipts
The documents are not limited to simple text. It will be in PDFs, scanned images, Excel files, HTML pages, emails, and API responses.
Each one behaves differently. PDFs often need layout analysis, images require OCR, and spreadsheets may have inconsistent columns.
Knowing how each format works helps in building a parser that doesn’t break when the real data comes in.
Statements, invoices, reports, legal docs. Often requires text extraction, OCR, and layout detection.
Receipts, ID proofs, handwritten forms. Needs OCR engines like Tesseract or cloud-based solutions.
Tables, transactions, logs. Relatively structured but can have inconsistent column headers.
Product pages, stock prices, job listings. Scraped using DOM parsers.
Standard API responses that need transformation into database-ready formats.
Headers, attachments, body content, OTPs, or form data extraction.
Each format needs dedicated tools and techniques.

Software development company priortizing serverless architecture for an array of reasons mentioning below:
No servers to manage
Automatic scaling
Pay only per execution
Event-driven processing
Let's understand how the process follows through serverless parser systems:
User uploads document → API Gateway triggers Lambda → File validated and stored in S3.
If password-protected, the user sends the password securely.
Lambda sends document to parsing API/engine → Extracts:
Structured data fields
Tables and lists
Dates and amounts
Named entities
Relationships between data points
Returns clean, structured JSON.
Lambda formats output → Returns to frontend → Deletes document from S3.
Total processing time: 2–5 seconds.
Parsing didn’t start with AI. It began with simple rules. If a line contains this word, extract this value. Those rules worked only when the document looked the same every time.
Today, document parser tools are much smarter. Machine learning and OCR help understand different layouts, table structures, and formats.
AI-based document parsers adapt better and handle a much wider range of documents without constant adjustments.
What it is: Fixed rules written directly in code using regex and line-by-line operations.
When it works: Simple invoices with templates that never change.
The problem: Breaks when format changes even slightly.
What it is: Multiple predefined templates, one for each document version.
When it works: Managing 5–50 variations of the same document type.
Used in: Banking forms, insurance documents, standard invoices.
What it is: All parsing rules stored in a database instead of hard-coded.
The advantage: Identify document version → load correct rules dynamically.
When it works: Enterprise-scale workflows, ETL pipelines, middleware systems.
What it is:
AI models understand documents like humans do, recognizing patterns, text, tables, and context automatically.
Popular Platforms:
Amazon Textract
Google Document AI
Azure Form Recognizer
Nanonets
Docsumo
Adobe Extract
What AI Handles:
Complex multi-page PDFs
Handwritten text
Tables with merged cells
Irregular layouts
Poor-quality scans
AI-based parsing is now the enterprise default due to accuracy and flexibility.
We have implemented our document parsing expertise in real world understanding the root issues and utilized the tech stack for best results.
Financial documents, legal contracts, medical records, invoices, etc. These are data goldmines trapped in PDFs. These documents contain critical information: transactions, dates, amounts, customer details, and more. But extracting this data manually? That's a nightmare.
For enterprise clients across fintech, healthcare, and legal sectors, we've built serverless parsers that let users upload documents and receive clean, structured JSON instantly.
The system we built runs without traditional servers. The process starts immediately whenever the document is uploaded. AWS takes charge of managing storage, scaling, and security in the backend.
Even when multiple files are waiting in a single queue to upload, this system architecture is rapid, stable, and modest.
AWS Lambda – Parsing logic
AWS S3 – Temporary file storage
API Gateway – REST endpoints
Node.js – Lambda runtime
OCR/AI APIs – Structured data extraction
We've built robust document parsers for enterprise clients across multiple industries:
Financial statements and invoices
Medical records and prescriptions
Legal contracts and agreements
Government forms and IDs
Insurance claims
Purchase orders and receipts
Academic transcripts
Technical drawings and schematics
Layout analysis
Template/version detection
Rule-based extraction
Error handling
JSON normalization
Quality checks
We combine:
In-house parsing logic
OCR engines (Tesseract, AWS Textract)
Third-party APIs
AI-based extraction (GPT-4, Claude)
Custom ML models
Result: Best accuracy + high speed at scale.
10,000+ documents/hour
Auto-scales to handle spikes
Parallel processing across multiple Lambda instances
98.5% first-pass accuracy
99.9% after quality checks
<0.1% error rate in production
$0.02 per document (average)
70% cheaper than traditional VM-based solutions
No idle infrastructure costs
Simple docs: 1-2 seconds
Complex docs: 3-5 seconds
Batch processing: 1000 docs in 5 minutes
That's wrap of process!
With document parsing, we get the following things to manage the unstructured data in a scannable format. Mentioning below:
Flexible: Compatible to support different formats, including PDFs, images, handwritten notes, or custom templates.
Reliable: If one extraction method is unavailable, the system automatically continues to another.
Cost-efficient: Serverless design enables payment only when documents are processed.
Scalable: Handles small batches or massive volumes without manual changes.
Easy to Maintain: Each layer works independently, so updates don’t disrupt the system.
CloudWatch Monitoring: Keeps an eye on system performance and flags issues early.
Industry Vertices: Suitable for all industry domains, fintech, healthcare, logistics, legal, and more.
Document parsing has become an integral part of regular operations. It enables processing complex data faster, within a few seconds, without interruption.
At Eternalight Infotech, we build scalable document parser systems that remain resilient, efficient, and active while handling large volumes of unstructured, inconsistent documents without bringing the system down.
No matter what kind of document it is: financial reports, medical records, contracts, or logistics documentation. The core structure does not manipulate; only the extraction rules change.
If your team is still wasting hours parsing manually, immediately switch to automated parsing to manage the scattered documents into helpful information.
Ready to automate your document workflows? Connect with us and let's get started.

Tarun Kumar
(Author)
Software Engineer
Contact us
Send us a message, and we'll promptly discuss your project with you.


